前言
从本篇文章开始,接下来的三篇文章,我们将实现音频编解码器功能模块,第一篇文章,也就是本文,我们将实现基于开源的IMA-ADPCM算法的音频编解码器,第二篇文章,我们将实现自定义的特色进度条以及简单介绍编码器的UI布局,在第三篇文章中 ,我们将实现编解码器的UI以及进度条与编解码器的消息传递。这三篇文章涉及到的知识点较多,比如ADPCM编解码的实现算法,python脚本使用subprocess调用C编译的exe可执行文件,python的多线程功能应用,线程之间的消息传递,还有特色进度条的实现等等。知识点很多,也是笔者自己一点一点摸索出来的,有许多不足的地方,还请多多指正批评。同时,模块的代码分布在三篇文章中,在第三篇文章的结尾,笔者会给出代码的存放的工程目录,这样大家就可以理解代码中的import模块导入。
本文开始讲述实现音频的编解码,目前笔者只写了一个算法,APDCM,产生笔者自写ADPCM的原因是笔者当初使用ffmpeg解一些经过ADPCM压缩后的数据,发现非常困难,不是因为ffmpeg没有ADPCM解码算法,而是它拥有太多ADPCM算法了,如果你安装了ffmpeg的话,使用命令ffmpeg -codecs可以查询ffmpeg内置的编解码库,关于ADPCM的就有如下:
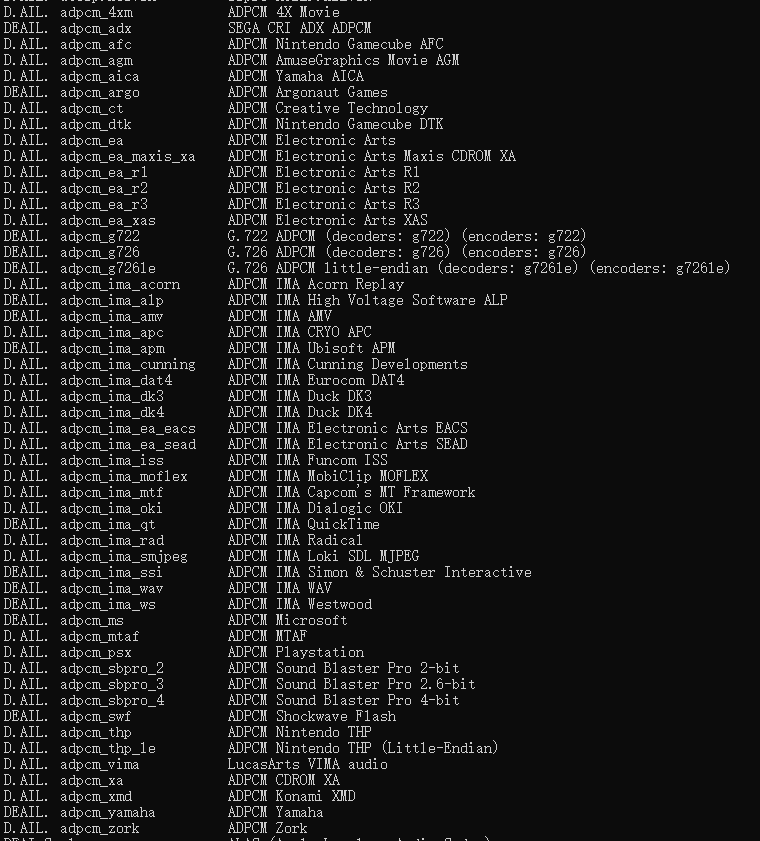
我并没有完全看完这些ADPCM算法各有哪些不同,笔者只对比过一些变种,如微软的ADPCM,adpcm_ms,它生成的二进制文件前会增加一些头部信息,指明其是由adpcm_ms编码的,其编码算法究竟和开源的ADPCM究竟有何不同,本文没有做详细的对比,但就其加的头部信息,就让其无法解码经过经典开源ADPCM算法编码的音频数据。因此笔者就根据开源的ADPCM算法,自行编写编解码器。
ADPCM算法原理
本文不对ADPCM算法做非常详细的数学推导,只介绍大概思想原理,如想了解更详细的原理,可以推荐可以去看看ADPCM(自适应差分脉冲编码调制)的原理和计算_单片机使用adpcm音频编解码算法-CSDN博客这篇文章。关于原理部分,笔者对这篇文章做一些简单地整理。
ADPCM(Adaptive Differential Pulse Code Modulation)自适应差分脉冲编码调制
ADPCM是DPCM的进阶版本,而DPCM是改良PCM而来的,我们先介绍PCM
PCM,脉冲编码调制,是声音模拟信号数字化的一种基础技术,本质上是将时间连续取值的模拟信号转换成离散的数字信号,即模数转换,事实上,“连续”这个词在机器上是非常难以实现的,现在大多数的“连续”,实际上都是快速且频繁的“离散”组成的,包括音频,视频等。过程就是采样,量化和编码。首先由硬件机器采样,将采样得到的信号幅度转换成数字(ADC)。PCM实际上就是一个大数组,数组中的每个值,代表了当前时间点上的模拟量强度。
在量化过程中会产生误差,一般而言,ADC的精度越高,失真越小,常见的量化数位8比特,16比特,32比特。
DPCM,差分脉冲编码调制,PCM是原始采样数据,即不对数据做压缩,保存的是最原始采样结果,这样的是数据量是比较大的,尤其在嵌入式设备中,硬件规格较低,在存储空间以及功耗方面都有比较严格的要求,传输PCM数据显然是不合适的。因此,我们需要对PCM数据进行压缩。
对音频数据归纳时可以看到,数据值与相邻的值通常相差不大,即过渡得比较平滑,不会忽高忽低,因此两点之间得差值不会太大,所以我们可以使用差值来表示下一个数据,而这个差值,可以用很少的位数(比如4比特)来进行表示,这样,如果PCM的量化位数位16比特时(一般会采用16比特),那么使用差分法将会把数据缩小成原来的1/4。
以8K的采样率为例,即1秒钟,机器采样8000次,量化精度为16比特,则1秒钟的数据量为 8000 * 16bit = 8000 * 2 byte = 128 000 bit = 128kb,如果用4bit表示差值,则1秒钟的数据仅需存储32kb左右的数据量。
DPCM存在一个问题,虽然音频数据大多数时候是比较平滑的,但是还是存在差值较大的情况,如果差值超过了4比特(-15,15),就无法很好地还原原来的数据,这时候如果增大差值宽度,例如将4比特调整为6比特或8比特,可以减少此问题的发送概率,但同样地,数据量增大了。
ADPCM的出发点就是解决DPCM的差值宽度问题,通过采用一个差值表(IMA ADPCM中使用89个固定差值,取值从7到32767),将差值的范围放宽到16bit,此时差值在数组中的编号只需要6bit就可以表示(0,88),再进一步只记录编号的变化值,就将变化量压缩到4bit。
16bit的 IMA ADPCM 编码产生的数据为一个数组, 数组中每个数都是4个bit(值范围为0x00到0x0F), 因为C语言编程中变量的最小单位是byte, 所以通常表示为 uint8_t 数组, 数组中每个元素存储2个 ADPCM 编码值, 或者对于32位系统使用 uint32_t, 每个元素存储8个 ADPCM 编码值.
对于IMA ADPCM, 还需要了解两个码表, 一个是差值步长码表, 一个是差值步长下标变化量码表
差值步长码表: 下标从0到88, 共89个值, 从小到大, 非均匀分布, 下标越大, 值之间的间隔越大, 这个码表的具体计算方式不清楚, 通过多次项拟合需要至少4次方到5次方才能拟合。 差值步长下标变化量码表: 下标从-7到7, ADPCM 队列中每个值可以通过这个直接查表得到下一个值的差值步长的下标变化量, 进而得到下一个值的差值步长. 值在 [-3, 3] 之间的, 变化都是-1, 也就是差值步长变小, 在[-4,-7]和[4,7]的, 变化是2,4,6,8, 可以看到对于-7和7, 差值步长会快速增大。
下面给出ADPCM解码和编码C程序
ADPCM解码代码
|
|
ADPCM编码代码
|
|
在代码中,已经把差分表以及步长表都放在了函数中
下面给出编码器与解码器共用的头文件
|
|
在这个头文件中,存放着一个结构体,adpcm_state,该结构体有两个变量,valprev表示预测值,index表示步长。
每次计算后,都会生成一个新的valprev和index,用以计算下一个值,因此,我们如果想要做一个编解码器,则必须向该程序中传递输入数组,adpcm_state以及数据长度。
上面是ADPCM的编码与解码算法,注意,上面的算法并不能直接构成一个可执行文件,因为没有main函数入口
因为我们的数据是通过python来进行读写的,因此我们要通过python将数据传入ADPCM编码器与解码器的入口,由入口对数据稍作处理,再传入ADPCM算法中进行运算,输出的结果由入口打印出来,打印的结果被python捕获并写入相应的文件中。
下面给出ADPCM编解码器的入口
AdpcmDecMain
|
|
我们能以解码器入口为例来解释代码,编码器入口同理:
- main函数接收参数,第一个参数无疑是函数名,第二个参数是
valprev,第三个参数是index,第四个参数往后是待解码的数据。 - 解释一下
strtol函数,argv[i]是输入参数,&endptr是一个指向char*的指针,它将在解析后指向第一个不属于数字部分的字符(如果整个字符串都是有效数字,它将指向字符串的末尾)。16是十六进制。 strtol函数会返回一个long类型的整数值,它是从字符串中解析出来的,如果字符串中包含无效字符,strtol将会在该字符串处停止解析,endptr将会指向该处。outdata做了冗余处理,根据经验,一语音帧最大138个字节。len是传入的待解码的数据长度,如若供有20个字节的待解码数据,则len=20- 有同学能猜出为什么循环打印
outdata要乘以2吗?总结时会给出解释。 - 将
outdata打印出来,被python脚本捕获,将valprev与index一起打印,被python脚本捕获,在下一轮数据来临时,带上valprev和index。 - 在这里敏锐的同学可能会注意到,我们在输入时,
valprev和index参数是放在数据前面的,而在输出时,则是放在数据后面的,使用的同学需注意这一点,并没有什么特殊含义,只是笔者当初脚本先传的valprev和index,而编解码器后给出这两个值,笔者没改过来而已。 - 在此轮解码结束后,编码器将结束生命周期,此时内存将全部释放,
valprev与index将会丢失,因此必须抛出给python脚本,以供下一次解码时使用
AdpcmEncMain
|
|
编码器入口与解码器入口大差不差,大家仔细阅读即可
编译
在本文中可以看到,我们采用了一个头文件,一个c文件存放编码算法,一个c文件存放程序入口这种形式来组织代码,这样的好处是方便整理代码,可读性更高,但同时呢,无法直接运行,因为编码算法的c文件与程序入口的c文件并没有链接到一起,因此程序入口无法找到adpcm_encoder和adpcm_decoder的函数实现,我们需要使用GCC命令来对文件进行手动编译。命令如下:
|
|
这条命令的作用是:
将AdpcmDecMain.c文件与AdpcmDec.c文件编译并链接在一起,生成一个名为AdpcmDecoder.exe的可执行文件
总结
这篇文章总的来说笔者不是很满意,因为并没有仔细解释ADPCM的原理,笔者认为ADPCM(自适应差分脉冲编码调制)的原理和计算_单片机使用adpcm音频编解码算法-CSDN博客这篇文章已经给出的非常详细,笔者解释只是锦上添花,而笔者也没有想到更好的理解方法,如果笔者后续对这些音频算法有更深的理解时,笔者会做出整理。
现在给出上面的问题的解释,为什么循环打印outdata要乘以2,这是因为,我们解码前的数据存储的是前一个数据与后一个数据的差分,仅用4bit存储,而解码后的单个PCM数据就有16bit,但在C语言中,最小存储单位为uint8_t,即8个比特,在本程序中,解码前的数据用char存储,也是8个比特,也就是说,一个indata能存储两个差分数据,即两个解码前的数据,outdata数组的数据类型是short即16个比特,一个解码的indata,解码后需要两个outdata来存储才行,这样,outdata的长度就是indata的2倍
为什么编码器的循环要除以4呢,同理,ADPCM的压缩比为4:1,至于为什么是4倍而不是两倍,主要是因为编码器的len是输入参数的两倍,这与解码器不同,与adpcm算法内部的len有关。
python脚本将在下一篇文章中展现,本文到这里就结束啦,祝大家变得更强!
因为语音编解码器功能模块的实现较为复杂,而且也增加了一些新的UI设计,因此知识点与代码都无法在一篇文章中全部呈现,但将代码分散在不同的文章里又让一些基础比较薄弱的同学难以快速上手,因此,如若对此模块感兴趣的人比较多,笔者将在这三篇文章的基础上,单独开一篇新的博文,梳理代码的布局以及如何在自己的机器上跑起来,让新手小白也能复制即用。